Summary
- What is X as Code
- How to write X as code IaC
- How do you execute the code changes on the infrastructure?
- What is GitOps
- How GitOps works?
- The CI/CD pipeline and the push or pull based deployments
- How to easy rollback with GitOps
- Git is the single source of truth
- How GitOps increases your IaC security
- Conclusion
The short explanation of GitOps is infrastructure is code done right with all the best practices.
Now let’s see a bit longer explanation. So it all starts with Infrastructure as Code.
As you know, the infrastructure’s code concept is when you define your infrastructure as code instead of manually creating it. This makes our infrastructure much easier to reproduce and replicate.
But note that infrastructure’s code actually evolved into defining not only infrastructure, but also network as code or policy as code and configuration is called, etc. So it’s not only about infrastructure anymore. These are all types of definitions as code or as they also call it, X as code.
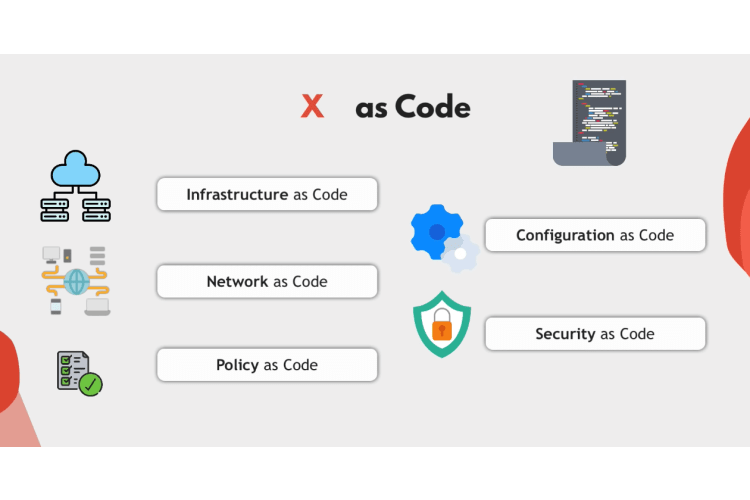
What is X as Code
So in X as code, Unified Infrastructure and Configuration Network, and so on in code. So for example, instead of manually creating servers and network and all the configuration around it on Aws and creating Kubernetes cluster with certain components, you define all of these in a terraform code or ansible code and Kubernetes manifest files.
And you have a bunch of Yaml files or other definition files that describe your infrastructure, your platform, and its configuration.
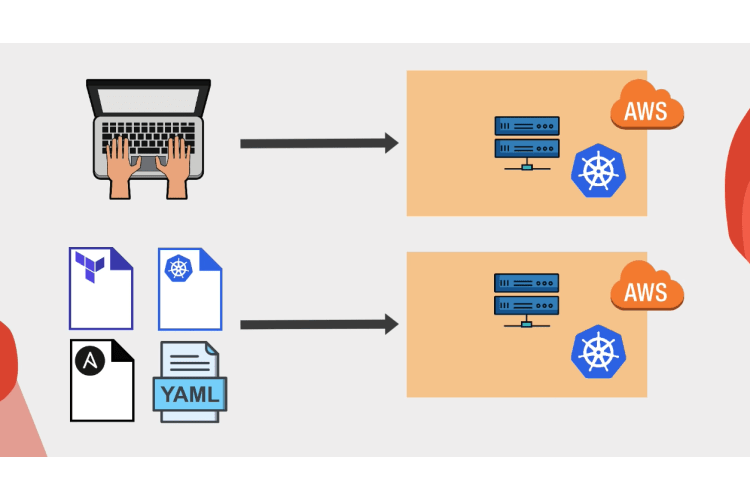
How to write X as code IaC
Now, how do many engineering teams write and use Infrastructure as Code or X as code?
You as a DevOps engineer, will probably create all these files locally on your machine. You try to test it, and once done, execute them also from your computer. So all these files are actually stored locally on your computer. Or you may even create a Git repository for your infrastructure as code and store all these files on Git So you have a version control for your infrastructure code and other team members can fetch the code as well and collaborate.
But when you make any changes to the code, you may not have a defined procedure like pull requests. You may just have a main branch and when you change the code, you commit it directly into the main branch as well as if someone else in the team changes code, they can commit directly into the main branch so no code reviews, no collaboration on the changes.
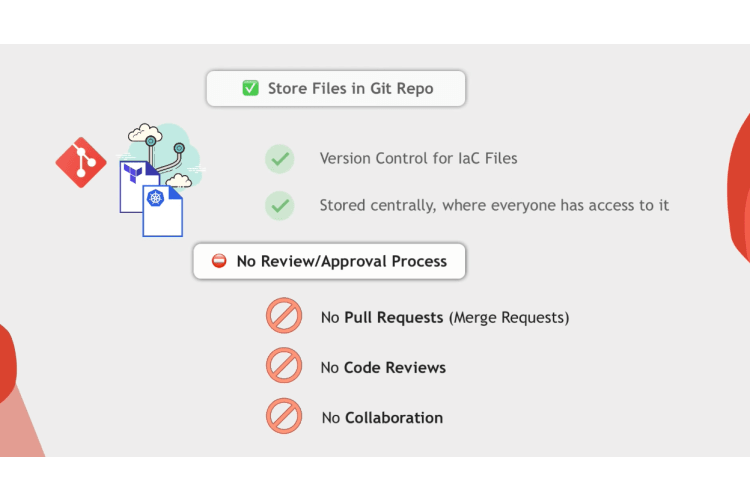
Also, when you commit your infrastructure’s code changes into the repository, no automated tests are running to test these code changes. Maybe you committed invalid Yaml files, or maybe you made a typo and the attribute names are wrong. Or maybe your code changes will break something in the infrastructure or your application environment.
How do you execute the code changes on the infrastructure?
Now, once you make the changes, how do you apply these changes on the actual infrastructure or a platform? How do you execute them? You’ll do it manually from your laptop.
You will do kubectl, apply or execute Terraform or Instable Command, etc. So to execute the code changes, each team member must access the Kubernetes Cluster or Aws infrastructure and apply changes there from their local machine. And this can make it hard to trace who executed what on the remote servers and have a history of changes applied to the infrastructure. And if you made any mistakes in the code wrong configuration, wrong attributes, you will know about these problems only once you apply them.
So untested config changes end up in the development environment where you can then test whether you broke something or not and after manually testing the changes on the development environment, you will then also from your local computer, apply the same changes to the staging and then production environments.
So even though we have an infrastructures code which already has lots of benefits, our process is still mostly manual and inefficient.
What is GitOps
So that’s where GitOps concept comes in to basically treat the infrastructure as code the same way as the application code. So in GitOps’s practice, we have a separate repository for the infrastructure is Code Project or Xs Code project and a full DevOps pipeline for it.

So let’s see how this works and more importantly, why is it so useful.
How GitOps works?
with Github’s infrastructure as code is hosted on a Git repository where it’s version controlled and allows team collaboration.
That’s the first step. Now, when you make changes instead of just pushing to the main branch, you go through the same pull request process as for your application code. So anyone in the team, including junior engineers, can create a pull request, make changes to the code, and collaborate with other team members on that pull request.
For these changes, you will have a CI pipeline that will validate the config files and test them just like you test application code changes. After testing these commits, other team members can approve the final changes. This could be developers or security professionals or other senior Operations engineers who will review and approve the pull request. This way, you have a tested, well-reviewed config changes before they get applied in any environment.
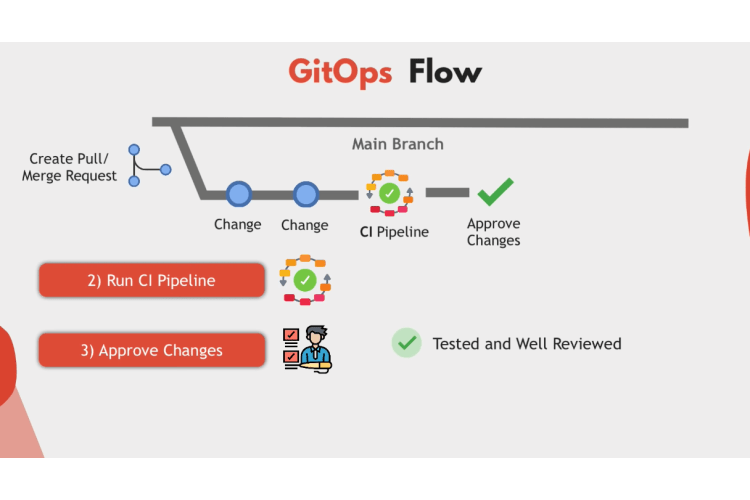
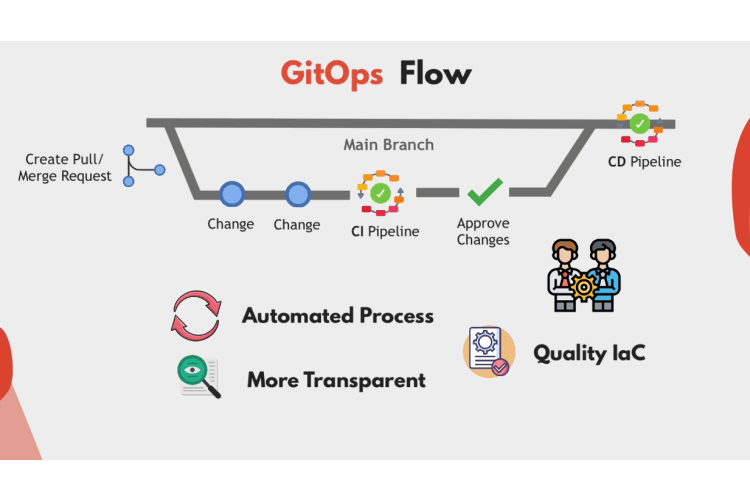
So only after that changes will be merged back into the main branch and through a CD pipeline get deployed to the environment. Whether it’s changing something in Kubernetes Cluster or updating the underlying Aws infrastructure.
So you have an automated process which is more transparent and produces high quality infrastructure or configuration code where multiple people collaborate on the change and things get tested rather than one engineer doing all the stuff from their laptop manually that others don’t see or can’t review.
The CI/CD pipeline and the push or pull based deployments
Now, we said that once merged into the main branch, the changes will be automatically applied to the infrastructure through a Cd pipeline. Right in GitOps. We have two ways of applying these changes. These are push or pull based deployments.
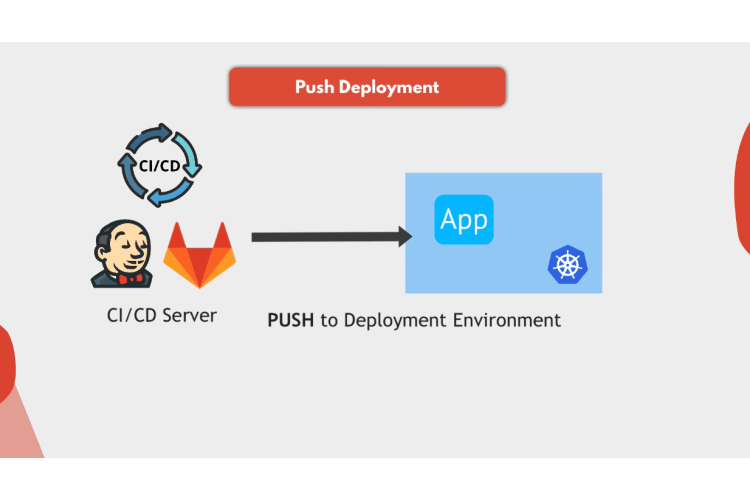
How push based deployment works?
Push-based deployments is what we traditionally know from the application pipeline on Jenkins or Gitlab, CI/CD, etc.
Application is built and pipeline executes a command to deploy the new application version into the environment.
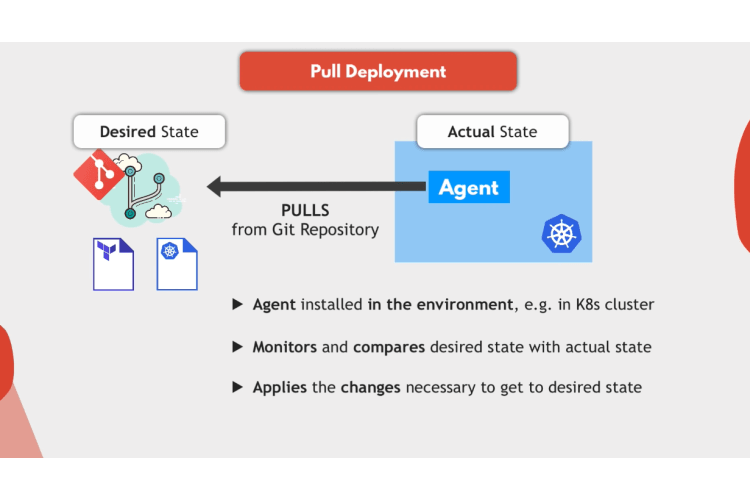
How pull based deployment works?
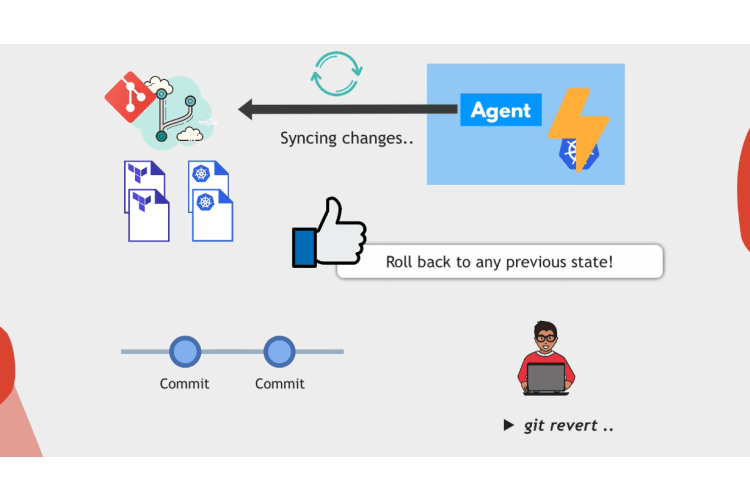
So what is a pool model? Here you have an agent installed in the environment like in Kubernetes cluster that actively pulls the changes from the Git repository itself.
The agent will check regularly what is the state of the infrastructure code in the repository and compare it to the actual state in the environment where it’s running. If it sees there is a difference in the repository, it will pull and apply these changes to get the environment from the actual state to the desired state defined in the repository.
Examples of Git Ops tools that work with the pool base model are Flux CD and Argo CD which run inside Kubernetes cluster and sync the changes from the Git repository to the cluster.
How to easy rollback with GitOps
Now, when you have the version control for your code and the changes in the repository are automatically synced to the environment, you can easily roll back your environment to any previous state in your code, and that could be another big advantage.
For example, if you make changes that break something in the environment so your cluster doesn’t work anymore, you can just do Git, revert, to undo the latest changes and get the environment back to the last working state.
Git is the single source of truth
So overall, this means that instead of spreading your infrastructure’s code and configuration is code, etc in different places and machines, and basically having those files just lying around on your computer, everything is stored centrally in a Git repository, and the environment is always synced with what’s defined in that repository.
And this means that Git repository becomes the single source of truth for your environment. And of course, this makes managing your infrastructure or your platform way easier.
How GitOps increases your IaC security
And finally, an important additional benefit is that Git Ops also increases security, because now you don’t have to give everyone in the team who needs to change something on the infrastructure or in Kubernetes cluster direct access to it to execute the changes because it’s the CD pipeline that deploys the changes.
Not individual team members from their laptops, but anyone on the team can propose changes to the infrastructure in the Git repository through pull requests. And once it’s time to merge that pull request and apply those changes, you can have a much narrower group of people who are allowed to approve and merge those changes into the main branch so that it gets applied.
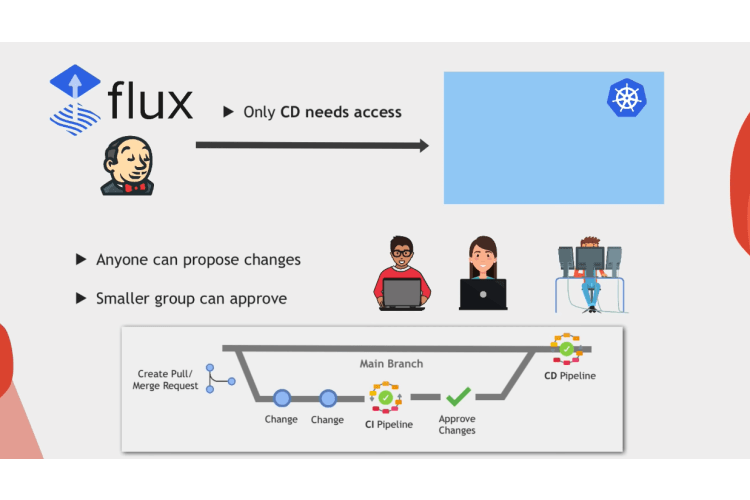
And as a result, you have less permissions to manage and a more secure environment.
Conclusion
So to summarize, Git Ops is an infrastructures code with version control, pull requests, and CI/CD pipeline. Now I hope you learned a lot in this video. Share with me in the comments. what is your experience and what do you think generally about GitOps.